ASICとは?アプリケーション固有集積回路とGPUの違い

ビットコインマイナーを開けて、中のチップを見てみると、ハッシュ計算だけを行うシリコンが見えます。それが唯一の仕事です。ウェブブラウザを実行することはできません。Netflixのストリームをデコードすることもできません。AIモデルをトレーニングすることもできません。しかし、その唯一の仕事であるハッシュ計算は、市販の汎用チップよりも約1000倍効率的に行います。この種のシリコンの名前はASIC、Application-Specific Integrated Circuitの略です。暗号通貨以外にも、多くの場所で使われています。Googleのデータセンター。あなたの携帯電話の無線モデム。テスラのオートパイロットコンピュータ。あなたのオフィスのすべてのイーサネットスイッチ。この記事では、ASICが実際には何であるか、どのように設計されるか、CPU、GPU、FPGAと何が違うか、なぜビットコインマイニングが2013年までにASICに落ち着いたのか、2026世代が最新のGPUと比べてどうなのかを解説します。
ASICとは何か、1段落で説明すると…
ASICとは、可能な限り最高のエネルギー効率で特定のタスクを実行するために設計されたチップです。ASICはApplication-Specific Integrated Circuitの略で、ハイフンなしでapplication specific integrated circuitと表記されることもあります。TSMCやSamsungなどのファウンドリでシリコンに設計がエッチングされると、ロジックを再プログラムすることはできません。すべてのトランジスタは、ASIC設計チームが配置した場所に正確に配置されます。徹底的な最適化と引き換えに、柔軟性は大幅に犠牲になっています。Antminer S21 Proのような最新のBitcoin ASICは、1テラハッシュあたり15ジュールで毎秒234兆回のSHA-256ハッシュを実行します。これは、CPU、GPU、その他の処理ユニットでは到底及ばないレベルです。GoogleのTPUはASICです。携帯電話の無線モデムもそうです。最新の家電製品でAIや機械学習を加速するデジタル信号ブロックもそうです。
ASICとCPU、GPU、FPGAの比較:汎用的なトレードオフ
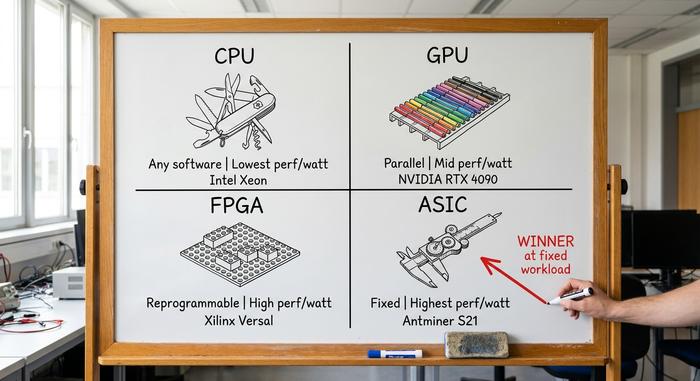
ASICの特長を理解する最も簡単な方法は、他の代替製品と比較してみることです。現代のコンピューティングでは、主に4種類のチップが用いられており、それぞれ柔軟性と効率性のトレードオフの比率が異なります。
CPU(中央処理装置)はノートパソコンのチップです。これまで書かれたあらゆるプログラムを実行できます。その代償として、ワットあたりの単一タスクの処理速度は特に速くありません。GPU(グラフィックス処理装置)は並列演算用に設計されています。同じ演算が数千個の小さなコアで同時に実行されます。これはグラフィックス、機械学習、ASIC耐性のある暗号通貨マイニングに最適です。FPGA(フィールドプログラマブルゲートアレイの略)は、VerilogやVHDLなどのハードウェア記述言語(HDL)を使用して製造後にロジックゲートを再プログラムできるチップです。FPGAはエネルギー効率の点でGPUとASICの中間に位置し、再構成可能であるという利点があります。ASICのコストはチップあたりではるかに低いですが、初期のNRE費用は莫大です。ASICは最終段階です。固定ロジック。ワットあたりの最大性能。柔軟性は全くありません。設計者は1つのワークロードに合わせてシリコンを最適化して完了とします。
| チップの種類 | 柔軟性 | 固定タスクにおけるワットあたりの性能 | 典型的な使用例 | 例 |
|---|---|---|---|---|
| CPU | あらゆるソフトウェアを実行できます | 最低 | オペレーティングシステム、一般的なコード | Intel Xeon、AMD Ryzen |
| GPU | SIMD並列、プログラマブル | 中 | グラフィックス、機械学習トレーニング、ASIC耐性マイニング | NVIDIA RTX 4090 |
| FPGA | 再プログラム可能なロジック | 高い | プロトタイピング、通信、HFT、少量カスタム | ザイリンクス・バーサル、インテル・アジレックス |
| ASIC | 固定機能シリコン | 最高 | BTCマイニング、Google TPU、ネットワークスイッチ | Antminer S21、Google TPU v5 |
この表を理解すれば、この記事の残りの部分は応用編です。ASICは、ワークロードが固定されていて、処理量が膨大で、テープアウトを正当化できるほどワークロードが長期間同じ状態を維持している場合に有利です。ワークロードが変化した瞬間に、ASICは不利になります。
ASIC開発:RTLからシリコンウェハまで
ASICの設計は時間がかかり、費用も高額で、ほぼ一方通行です。パイプラインは大きく分けて6つの段階に分かれており、どれか一つでもつまずけば、数ヶ月の作業と数千万ドルものマスク費用を無駄にしてしまう可能性があります。
第1段階は仕様とアーキテクチャです。エンジニアはチップが何をすべきかを明確にします。パフォーマンス目標、電力バジェット、ダイ面積などです。第2段階はRTL設計で、エンジニアはハードウェア記述言語でレジスタ転送レベルのロジックをプログラミングします。VerilogとVHDLは依然として主流です。SystemVerilogは検証を担うようになりました。第3段階は機能検証そのものであり、テストベンチに対するシミュレーションと形式的なプロパティチェックの組み合わせです。この段階で発見されたバグは数千ドルの損失で済みますが、シリコンに紛れ込んだバグは数百万ドルの損失になります。ゲームのすべてはこの段階にあります。
第4段階は論理合成です。コンパイラはRTLを標準セルのゲートレベルネットリストに変換します。第5段階は物理設計です。フロアプランニング、配置、配線、クロックツリー合成、タイミングクロージャを行います。出力は、チップの各レイヤーを記述したGDSIIファイルです。第6段階はテープアウトで、GDSIIファイルはファウンドリに送られます。フォトリソグラフィ工程で、設計はマスクセットに変換されます。マスクはシリコンウェハを層ごとにパターン化します。最後に、ウェハは個々のチップにダイシングされ、パッケージ化されます。この規模のトランジスタ間の相互接続でさえ、それ自体が研究分野であり、毎年博士号が執筆されています。
さて、費用について。5 nm ノードのマスク セット 1 個で 500 万ドルから 1000 万ドル。3 nm では、Semianalysis と IBS によると 1000 万ドルから 1500 万ドル以上。給与、IP ライセンス、検証を加えると、最先端の ASIC の NRE 費用は簡単に 5 億ドルを超えます。仕様から最初のシリコンまでのサイクルタイム: 12 ヶ月から 24 ヶ月。実際に重要なツール ベンダー: Synopsys (VCS、PrimeTime)、Cadence (Virtuoso)、Siemens EDA。Verilog と VHDL は 40 年経っても依然として業界を支配しています。これらに取って代わるものはまだありません。
設計されたASICの種類:フルカスタム、ゲートアレイ、その他
ASICの設計手法には、さまざまな種類が存在する。それらは、綿密なフルカスタム設計から、迅速な既製設計まで多岐にわたる。
フルカスタムASICは、すべてのトランジスタを手作業で描画します。最高の性能と密度を実現します。設計時間は最も長くなります。標準セルまたはセミカスタムASICは、事前に特性が付けられたロジックゲート、レジスタ、およびメモリブロックのライブラリを使用します。これにより、開発時間が桁違いに短縮され、ほとんどのデジタルワークロードでほぼ最適な結果が得られます。ゲートアレイASICはさらに進んでいます。トランジスタが接続されていないプレファブリケーションウェハを使用し、それらを配線する金属層のみが顧客固有です。コストと納期の両方が削減されます。構造化ASICは、ゲートアレイと標準セルの中間に位置し、少量生産で高性能な設計の中間的な道です。
少し歴史を振り返ってみましょう。バイポーラゲートアレイは1967年にフェランティとインターデザインによって登場し、フェアチャイルドのマイクロマトリックスファミリーも同年発売されました。1981年に発売されたシンクレアZX81ホームコンピュータに搭載されたフェランティULAは、最初の普及型民生用ASICとして広く知られています。CMOSゲートアレイは1974年に登場し、1980年代を通じてフルスタンダードセルASICが普及しました。今日の最先端ASICも、この系譜を受け継いでいます。
現在ASICが使用されている分野:TPU、ネットワーク、AI推論
ASICは至るところに存在し、人々はもはや見向きもしなくなっている。スマートフォンを開けば、カスタムアプリケーションプロセッサが見つかるだろう。技術的には、これはASICファミリーの一種だ。AppleのAシリーズとMシリーズ。QualcommのSnapdragon。SamsungのExynos。クラウドデータセンターに足を踏み入れれば、Broadcom、Cisco、MarvellのカスタムネットワークASICが、毎秒テラビットのトラフィックをスイッチを通して処理しているのがわかる。もし同じ処理をソフトウェアで行おうとしたら、スイッチは溶けてしまうだろう。
最もよく引用される現代の非暗号ASICは、GoogleのTensor Processing Unitです。TPUプロジェクトは、コンセプトからシリコンの展開まで約15か月で完了しました。TPU v1は2015年にGoogleのデータセンターで稼働を開始し、2016年5月のGoogle I/Oで一般に公開されました。Norm Jouppiのチームによる2017年のISCA論文では、TPU v1は当時のCPUやGPUよりも15~30倍高速な推論を実行し、ワットあたりのパフォーマンスは30~80倍優れていると報告されています。Googleは現在、エージェントAI時代をターゲットとした第8世代のTPU、Ironwoodを使用しています。Edge TPUは2018年7月に出荷され、エッジでの低消費電力推論に同じアイデアをもたらしました。
自動車用ASICも至る所にあります。テスラのDojoトレーニングチップと、同社の車に搭載されているFSD推論チップはどちらもカスタムASICです。MobileyeとNVIDIAは、ADASシステムにおける画像処理とデジタル信号処理用のASICアクセラレータを出荷しています。通信、自動運転車、AI推論。これらはASICが広く使用され、今後10年間も支配し続ける3つの成長分野です。ASICは製造後に再プログラムできないため、ワークロードが実際に固定されている場所に展開されます。4つ目は、この記事がずっと指摘してきた仮想通貨マイニングです。
ASICマイナー:Avalon1が語るビットコインの集積回路物語
ビットコインマイニングは、ASICがなぜ重要なのかを最も分かりやすく示す事例と言えるでしょう。ビットコインネットワークは、マイナーにSHA-256ハッシュの計算を依頼し、報酬を支払います。SHA-256は固定されており、2009年以降変更されていません。そのため、ASICにとって格好の標的となるのです。
初期の頃は、マイニングは家にあったハードウェアで行われていました。CPUマイニングは2009年から2010年にかけてピークを迎えました。2010年から2012年にかけては、グラフィックカードがCore i7よりも桁違いに高速にハッシュできることが分かると、GPUが主流となりました。2011年から2012年には、熱心なマイナーのためにFPGAの短い期間が開かれました。そして2013年1月19日、Canaan Creative社が商用生産された初のBitcoin ASICであるAvalon1を出荷しました。最初のユニットは110nmプロセスで製造され、600ワットで60GH/sを達成しました。当時、世界のBitcoinネットワーク全体では約20TH/sで稼働していたため、Avalon1 1台で発売当初は1日あたり15~20BTCをマイニングできると推定されました。私たちが知っているマイニングビジネスは、まさにこの日から始まったと言えるでしょう。
Bitmainは同年、北京でJihan WuとMicree Zhanによって設立された。MicroBT(Whatsminerブランド)は2016年に、元BitmainエンジニアのYang Zuoxingによってスピンアウトして設立された。2013年後半には、GPUによるビットコインマイニングはすでに採算が合わなくなっていた。CPUによるマイニングは2年前にすでに廃れていた。それ以来、ビットコインをマイニングする経済的に合理的な方法はASICを使うことだけになった。それだけだ。
業界の統合は急速に進んでいる。Bitmainは現在、世界のASICマイナー市場の約82%を占めていると推定されている。2024年、米国は中国製ASICマイニング機器に25%の通商法301条に基づく関税を課した。これにより、マイナーが機器を配備する場所やASICチップの製造拠点が再編された。半導体事業の仮想通貨分野は、今や米中貿易摩擦の渦中に位置づけられている。

ASICとGPUマイニングの比較(2026):ハッシュレート、ワット数、ROI
2026 のビットコインにおいて、ASICマイナーとGPUを比較するのは競争ではなく、カテゴリーの誤りです。数字を見ればその理由がわかります。
5月2026日現在、Fortuneのデイリー価格トラッカーによると、ビットコインは1コインあたり約77,347ドルで取引されています。ハッシュレートインデックスによると、ネットワークハッシュレートは7日間平均で約1,012 EH/sです。難易度は136.61 T付近で推移しています。ブロック報酬は、2024年4月19日の半減期以降、3.125 BTCとなっています。ハッシュ価格(マイナーがハッシュパワー1単位あたりに得る収益)は、1PH/s/日あたり39.04ドルで、これは1TH/日あたり約0.039ドルに相当します。
| モデル | ハッシュレート | 効率 | 力 | 冷却 | 1日あたりの収益は0.039ドル/TH |
|---|---|---|---|---|---|
| Antminer S21 Pro | 234 TH/秒 | 15 J/TH | 西3,510 | 空気 | 約9.13ドル |
| Antminer S21 XP Hydro | 473 TH/秒 | 12 J/TH | 5,676 W | 水 | 約18.45ドル |
| Whatsminer M60S++ | 226 TH/秒 | 15.93 J/TH | 3,600W | 空気 | 約8.81ドル |
| Whatsminer M63S+ | 450 TH/s | 17 J/TH | 7,650 W | 水 | 約17.55ドル |
大規模農場で一般的な料金である1kWhあたり0.07ドルを当てはめると、S21 Proは1日あたり約84kWhを消費し、コストは約5.88ドルになります。エネルギーの純額は1日あたり数ドルです。現在のハッシュ価格でS21 Proの損益分岐点となる電気料金は、1kWhあたり約0.108ドルです。ケンブリッジ代替金融センターによると、ネットワーク全体では年間推定170~180TWhを消費し、これは世界の電力の約0.7~0.8%に相当します。
次にGPU側を見ていきましょう。前世代のコンシューマー向け最高峰カードであるNVIDIA RTX 4090は、Bitcoin SHA-256を約1〜2 GH/sで計算します。これは0.001〜0.002 TH/sに相当し、S21 Proの234,000 GH/sとは大きな差があります。S21 Proは1,600ドルのグラフィックカードよりも10万倍以上高速です。また、動作音は75 dBで、道路脇の掃除機の騒音レベルとほぼ同じですが、ハイドロモデルでは50 dBまで下がります。SHA-256に関しては、汎用チップは不要です。
2026におけるGPUマイニング可能なコイン:GPUが依然としてASICに勝る場所
2026 の時点でも、少数のプルーフ・オブ・ワークのコインが依然としてGPUをゲームに残しているが、これは主に、それらのアルゴリズムがASICシリコンに敵対するように設計されているためである。
Ergo は Autolykos2 というメモリ負荷の高いアルゴリズムを使用しており、初日から GPU 専用のままです。Ravencoin は KawPow を使用しています。Ravencoin では RTX 4090 で約 120 MH/s の性能を発揮します。Alephium は Blake3 を使用しており、実際には GPU 専用のままです。Monero は RandomX に依存しており、これは意図的に CPU 専用で、乱数生成を中心に構築されているため、ASIC の利点はなくなります。Kaspa は、IceRiver と Bitmain が専用の kHeavyHash ASIC を出荷した 2023 年に ASIC 耐性を失いました。Ethereum Classic の Ethash は 2018 年以来 ASIC マイニングされています。Zcash の Equihash はそれより何年も前に ASIC に侵食されました。
そのパターンは一貫している。メモリ負荷の高いアルゴリズムや頻繁にローテーションされるアルゴリズムは、長年にわたりASICによる置き換えに抵抗する。一方、固定計算負荷の高いアルゴリズムは必ず衰退する。これはシリコン経済の原理であり、それ以上でもそれ以下でもない。




