Apa Itu DeepSeek AI? Model Terbuka yang Mengguncang Dunia Kripto

Sebuah aplikasi gratis dari perusahaan rintisan Tiongkok yang kurang dikenal berhasil melakukan sesuatu yang belum pernah terjadi sebelumnya dalam krisis kripto. Dalam satu hari, aplikasi itu menghapus $589 miliar dari Nvidia , kerugian satu hari terbesar bagi perusahaan mana pun dalam sejarah pasar saham AS. Dan dampaknya tidak berhenti di Wall Street. Bitcoin merosot 7 persen, lebih dari $300 miliar menguap dari total pasar kripto, dan token AI mengalami penurunan paling tajam.
Aplikasi tersebut adalah DeepSeek. Model di baliknya, DeepSeek R1, adalah model AI terbuka dan murah yang cukup baik untuk menggoyahkan asumsi yang menopang perdagangan AI dan sebagian besar kripto: bahwa membangun kecerdasan buatan yang kuat membutuhkan banyak chip mahal. Panduan ini menjelaskan apa sebenarnya DeepSeek AI, bagaimana ia melakukan begitu banyak hal dengan begitu sedikit, bagaimana perbandingannya dengan ChatGPT, dan mengapa ia mengirimkan getaran ke token kripto AI yang masih terasa hingga saat ini.
Apa itu DeepSeek AI dan siapa yang membangunnya?
DeepSeek adalah laboratorium kecerdasan buatan asal Tiongkok, tetapi awalnya bukan sebagai laboratorium. Perusahaan ini tumbuh dari sebuah hedge fund, dan latar belakang tersebut menjelaskan hampir semua hal tentang cara berpikirnya.
Dari dana lindung nilai kuantitatif hingga laboratorium AI
DeepSeek didirikan pada 17 Juli 2023 di Hangzhou, Tiongkok, oleh Liang Wenfeng. Liang sebelumnya telah menjalankan High-Flyer, sebuah hedge fund kuantitatif yang memperdagangkan pasar menggunakan pembelajaran mesin dan telah menimbun sejumlah besar GPU Nvidia untuk tujuan tersebut. Ketika chip-chip tersebut tidak digunakan untuk perdagangan, ia mengarahkannya ke model bahasa. Jadi, DeepSeek memulai kiprahnya dengan daya komputasi yang murah, tim peneliti, dan tanpa tekanan investor untuk mengejar model sebesar mungkin. Perusahaan ini tetap ramping, hanya dengan sekitar 160 karyawan, dan belajar untuk memaksimalkan hasil dari perangkat keras. Efisiensi bukanlah slogan pemasaran. Itu adalah keseluruhan budaya perusahaan. Ada ironi yang perlu dicatat. High-Flyer telah menimbun chip-chip tersebut sebagian sebelum adanya kontrol ekspor AS yang kemudian memutus akses Tiongkok ke GPU terbaik Nvidia. Karena terpaksa melakukan lebih banyak hal dengan chip yang lebih lemah dan lebih sedikit, para insinyur DeepSeek menjadi sangat mahir dalam penghematan, dan kendala tersebut menjadi keuntungan.
Keluarga model: V3, R1, dan V4
DeepSeek dirilis dengan cepat. DeepSeek Coder hadir pada akhir tahun 2023, V2 pada Mei 2024, dan DeepSeek V3 yang fenomenal pada Desember 2024. Kemudian muncul DeepSeek R1 pada 20 Januari 2025, model penalaran yang memicu perkembangan pesat. Pada April 2026, laboratorium telah mempratinjau DeepSeek V4, dengan V4-Pro dan V4-Flash yang lebih ringan, mendorong jendela konteks hingga mendekati satu juta token. Setiap rilis mengikuti strategi yang sama: sesuaikan dengan batasan kemampuan, kenakan biaya sebagian kecil, dan berikan bobotnya secara gratis.
Open weights, API, dan deepseek.com
Bagian terakhir itu penting. Sejak R1, model DeepSeek telah dirilis di bawah lisensi MIT yang permisif sebagai unduhan open-weight di Hugging Face dan GitHub. Siapa pun dapat mengambilnya, memeriksanya, menyempurnakannya, atau menjalankannya di mesin mereka sendiri. Anda juga dapat menggunakan chatbot secara gratis di deepseek.com atau terhubung ke API DeepSeek dengan biaya yang sangat murah. Open weight ditambah API yang murah adalah kombinasi yang langka, dan itulah mesin di balik perubahan besar ini.

Bagaimana DeepSeek R1 dan V3 sebenarnya bekerja
Reputasi DeepSeek bertumpu pada fakta sederhana yang canggung bagi para pesaingnya. DeepSeek mampu menandingi model yang jauh lebih besar dan lebih mahal, namun menggunakan daya komputasi yang jauh lebih sedikit. Kuncinya terletak pada arsitektur—bukan sihir.
Gabungan para ahli dan inferensi yang efisien
DeepSeek V3 memiliki 671 miliar parameter, tetapi tidak menggunakan semuanya sekaligus. Ini adalah model campuran pakar, jadi untuk setiap token tertentu, ia hanya mengaktifkan sekitar 37 miliar parameter, segelintir "pakar" yang relevan dengan tugas tersebut. Laboratorium tersebut menggabungkannya dengan perhatian laten multi-kepala, sebuah metode yang mengkompresi memori selama inferensi. Hasilnya adalah model raksasa yang berjalan seperti model kecil. Memori lebih sedikit, daya lebih rendah, biaya per jawaban lebih rendah. Bagi pesaing yang menghabiskan miliaran dolar dengan asumsi bahwa yang lebih besar selalu berarti lebih mahal, ini adalah bukti konsep yang tidak diinginkan.
R1, penalaran, dan rangkaian pemikiran
DeepSeek R1 menambahkan trik kedua: ia berpikir keras. Seperti o1 milik OpenAI, ini adalah model penalaran yang memecahkan masalah langkah demi langkah menggunakan rantai pemikiran sebelum memberikan jawaban. Itulah mengapa ia mencetak skor sangat baik pada tugas-tugas sulit. R1 mencapai 97,3 persen pada benchmark MATH-500 dan 79,8 persen pada AIME 2024, dan menyelesaikan 49,2 persen masalah GitHub nyata di SWE-bench , menempatkannya sejajar dengan yang terbaik dari OpenAI pada saat itu.
Klaim biaya pelatihan sebesar $5,6 juta, diuraikan secara rinci.
Berikut angka yang menggemparkan internet. Makalah DeepSeek sendiri menyatakan bahwa proses pelatihan akhir untuk V3 menghabiskan biaya sekitar $5,58 juta untuk waktu GPU. Jika dibandingkan dengan $100 juta yang banyak dikutip untuk GPT-4, angka tersebut tampak memalukan. Tetapi bacalah detailnya. Angka tersebut hanya mencakup proses akhir, bukan penelitian, eksperimen yang gagal, atau chip itu sendiri. Analis di SemiAnalysis memperkirakan pengeluaran perangkat keras DeepSeek yang sebenarnya jauh di atas $500 juta. Judul berita itu akurat dan menyesatkan pada saat yang sama, dan itulah sebabnya berita tersebut menyebar begitu luas.
| Model DeepSeek | Dilepaskan | Jenis | Catatan |
|---|---|---|---|
| DeepSeek V3 | Desember 2024 | MoE LLM | 671B parameter, 37B aktif, MIT |
| DeepSeek R1 | Januari 2025 | Pemikiran | Kelas terbuka, bersaing dengan OpenAI o1 |
| DeepSeek V4 | April 2026 | Keluarga MoE | V4-Pro dan V4-Flash, konteks ~1 juta |
DeepSeek AI vs ChatGPT, Claude, dan Gemini
Jadi, apakah DeepSeek lebih baik daripada ChatGPT? Itu tergantung pada kebutuhan Anda. Dalam hal matematika, pengkodean, dan penalaran mentah, DeepSeek mampu bersaing dengan model-model terbaik dari OpenAI dan Anthropic. Kekurangannya terletak pada kualitas penulisan, input multimodal, dan kepercayaan. Model unggulan DeepSeek sebagian besar hanya berbasis teks, sementara ChatGPT menangani gambar, suara, dan video. Gaya penulisan OpenAI masih lebih halus untuk penulisan sehari-hari. Gemini milik Google berada di antara keduanya, kuat dalam input multimodal dan pencarian, tetapi lebih lemah dalam akses terbuka. Dan bagi banyak bisnis Barat, faktor penentu bukanlah tolok ukur sama sekali, melainkan kepercayaan: model yang dilatih dan dihosting di Tiongkok membawa beban yang tidak dimiliki oleh model yang dihosting di AS.
Kemudian ada soal harga, di mana selisihnya tidak terlalu besar. Tabel di bawah ini menjelaskan semuanya, dan inilah alasan mengapa para pengembang terus memindahkan beban kerja mereka ke API DeepSeek.
| Model | Masukan / 1 juta token | Beban terbuka | Multimodal |
|---|---|---|---|
| DeepSeek V3.2 | ~$0,28 | Ya (MIT) | TIDAK |
| GPT-5.2 (OpenAI) | ~$1,75 | TIDAK | Ya |
| Claude (Antropis) | Tingkat premium | TIDAK | Ya |
Untuk teks dan kode dalam skala besar, DeepSeek kira-kira enam kali lebih murah dalam hal input dibandingkan GPT-5.2, dan karena bobotnya terbuka, Anda dapat melewati API sepenuhnya dan menjalankannya melalui penerapan lokal. Hal itu menjadikan DeepSeek pilihan yang sangat hemat biaya, dan sulit bagi laboratorium tertutup untuk menjawabnya.
Momen DeepSeek yang mengguncang dunia kripto.
Marc Andreessen menyebutnya sebagai "momen Sputnik-nya AI." Dia berbicara tentang kebanggaan nasional, tetapi pasar mendengar sesuatu yang lebih dingin — mungkin hal yang paling berharga dalam AI bukanlah tumpukan chip sama sekali.
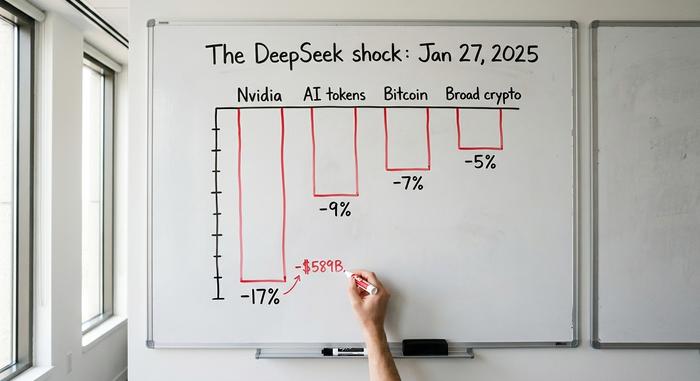
$589 miliar hilang dalam sehari
Ketika DeepSeek menduduki puncak App Store AS pada 27 Januari 2025, dengan 16 juta unduhan dalam 18 hari pertama, para pedagang melakukan perhitungan terbalik. Jika sebuah laboratorium Tiongkok dapat mencapai batas teknologi tersebut hanya dengan sebagian kecil perangkat keras, permintaan masa depan untuk chip Nvidia tiba-tiba tampak lebih goyah. Saham Nvidia jatuh sekitar 17 persen pada hari itu dan kehilangan nilai pasar sebesar $589 miliar , kerugian satu hari terbesar dalam sejarah AS. Seluruh Nasdaq pun terpukul.
Mengapa token kripto AI mengalami penurunan paling tajam?
Kripto pun tak luput dari dampaknya. Bitcoin turun sekitar 7 persen menjadi sekitar $97.750, dan lebih dari $300 miliar meninggalkan pasar kripto secara keseluruhan. Namun, kerugian terbesar terjadi pada token AI. Kategori ini turun sekitar 9 persen pada hari itu, dibandingkan dengan sekitar 5 persen untuk pasar secara luas, dengan Render turun 12,6 persen dan Fetch.ai turun sekitar 10 persen. Alasannya cukup mengkhawatirkan. Sebagian besar nilai token AI bergantung pada narasi yang sama dengan Nvidia: AI membutuhkan daya komputasi yang besar, daya komputasi langka, jadi apa pun yang menjual daya komputasi atau GPU sangat berharga. DeepSeek membongkar narasi tersebut, dan token yang paling bergantung padanya mengalami kerugian paling besar. Penurunan itu sendiri tidak berlangsung lama; dalam beberapa hari Bitcoin berhasil memulihkan sebagian besar kerugiannya karena para analis menyebut kepanikan itu sebagai reaksi berlebihan. Tetapi sektor token AI tetap goyah jauh lebih lama, sebuah tanda bahwa pasar sedang menilai ulang seluruh narasi tersebut, bukan hanya mengalami penurunan yang buruk.
Token kripto AI setelah DeepSeek
Inilah poin pentingnya. Guncangan yang sama yang menghantam token AI juga memberi mereka argumen jangka panjang. Jika model-model mutakhir dapat murah dan terbuka, maka benteng pertahanan laboratorium-laboratorium besar yang tertutup akan menyusut, dan infrastruktur AI yang terbuka dan tahan sensor mulai terlihat lebih berharga, bukan sebaliknya. Jaringan komputasi terdesentralisasi seperti Akash , jaringan rendering seperti Render, dan pasar kecerdasan mesin seperti Bittensor semuanya menawarkan dunia di mana AI tidak terkunci di dalam tiga perusahaan Amerika. DeepSeek membuat dunia itu terasa lebih dekat. Bittensor, yang token TAO-nya memberi penghargaan kepada jaringan model pembelajaran mesin yang bersaing, adalah taruhan paling jelas pada gagasan tersebut: pasar untuk kecerdasan terbuka daripada satu otak perusahaan. Apakah jaringan-jaringan ini benar-benar dapat menghasilkan AI kelas mutakhir masih belum terbukti, tetapi DeepSeek mengalihkan beban keraguan ke laboratorium-laboratorium tertutup.
Pasar pun memperhatikan. Pada Mei 2025, Grayscale telah meresmikan Sektor Kripto AI khusus yang mencakup 20 token senilai sekitar $21 miliar secara gabungan, meningkat sekitar 4,7 kali lipat dari $4,5 miliar pada awal tahun 2023. Namun, berhati-hatilah. Peluncuran ini juga menarik para penipu: dalam satu hari, lebih dari 75 memecoin "DeepSeek" palsu muncul, dan para pedagang yang mengejarnya kehilangan lebih dari $100 juta . DeepSeek tidak pernah meluncurkan token. Klaim apa pun yang menyatakan sebaliknya adalah jebakan.
Apakah DeepSeek AI aman digunakan? Larangan dan privasi
Di sinilah kehati-hatian terbukti penting. Gunakan aplikasi atau situs web resmi DeepSeek dan data Anda, termasuk perintah yang Anda berikan, akan dikirim ke server di Tiongkok dan ditangani di bawah kebijakan privasi yang diatur oleh hukum Tiongkok. Beberapa pemerintah memutuskan bahwa itu adalah masalah. Italia memblokir DeepSeek pada 30 Januari 2025 karena masalah perlindungan data. Lebih dari selusin negara bagian AS melarangnya dari perangkat resmi hingga awal 2025, dan Kongres memperkenalkan Undang-Undang Larangan DeepSeek pada Perangkat Pemerintah. Model ini juga mencerminkan aturan konten Tiongkok, yang menghindari atau menyensor topik-topik yang sensitif secara politik. Metode DeepSeek juga menuai kritik. Pada awal tahun 2020, Anthropic menuduh laboratorium tersebut menggunakan ribuan akun palsu untuk mengumpulkan jutaan percakapan Claude untuk pelatihan, tuduhan yang dibantah oleh DeepSeek. Kisah tentang kejeniusan yang hemat ini memiliki sisi yang diperdebatkan.
Semua itu tidak membuat teknologi itu sendiri tidak aman untuk dijalankan. Karena bobotnya terbuka, pengguna atau perusahaan yang peduli dengan privasi dapat mengunduh model tersebut dan menjalankannya secara lokal, tanpa data yang keluar dari gedung. Aplikasi yang dihosting adalah risikonya. Model terbuka adalah jalan keluarnya.
Cara menggunakan DeepSeek AI: penerapan lokal
Anda memiliki tiga cara untuk mengaksesnya. Cara termudah adalah melalui chatbot gratis di deepseek.com atau aplikasi seluler, cocok untuk pertanyaan santai jika Anda tidak mempermasalahkan privasi. Cara kedua adalah melalui DeepSeek API, cukup murah sehingga pengembang dapat menggunakan API ini untuk menangani beban kerja yang berat; dokumentasi DeepSeek API akan memandu Anda dalam pengaturan, dan DeepSeek Coder dirancang untuk pemrograman. Cara ketiga, dan yang paling aman untuk pekerjaan sensitif, adalah penerapan lokal: ambil beban kerja terbuka dari Hugging Face atau jalankan versi yang lebih kecil melalui alat seperti Ollama di perangkat keras Anda sendiri. Modelnya sama, tanpa paparan data. Untuk pertanyaan santai, aplikasi gratis sudah cukup; bagi siapa pun yang menangani data pribadi atau data yang diatur, cara lokal sepadan dengan pengaturan tambahan.
Apa arti DeepSeek bagi AI dan kripto?
Pelajaran abadi dari DeepSeek tidak ada hubungannya dengan kemenangan China dalam satu putaran. Pergeseran sebenarnya adalah bahwa AI mutakhir menjadi murah dan terbuka lebih cepat daripada yang diperkirakan siapa pun. Bagi pengguna biasa, itu berarti alat yang lebih baik dengan biaya lebih rendah. Bagi laboratorium tertutup, itu berarti keunggulan GPU lebih tipis daripada yang diasumsikan oleh valuasi mereka. Dan untuk kripto, ini berlaku dua arah: token AI yang dibangun di atas cerita kelangkaan mengalami penurunan, sementara token yang membangun infrastruktur AI terbuka dan terdesentralisasi mendapatkan alasan baru untuk eksis. Jadi pertanyaan sebenarnya bukanlah apakah DeepSeek itu bagus. Jelas itu bagus. Pertanyaannya adalah siapa yang masih dibayar ketika kecerdasan buatan berhenti menjadi mahal.




