नाममात्र बनाम क्रमसूचक डेटा: मुख्य अंतरों को समझना

इस खंड में, पाठक जानेंगे कि नाममात्र डेटा और क्रमिक डेटा में क्या अंतर है, आधुनिक डेटा विज्ञान में ये श्रेणियाँ क्यों महत्वपूर्ण हैं, और उनकी भूमिकाओं को समझने से सटीक डेटा विश्लेषण और सांख्यिकीय व्याख्या कैसे बेहतर होती है। आप जानेंगे कि प्रत्येक डेटा प्रकार मापन पैमानों को कैसे प्रभावित करता है, नाममात्र और क्रमिक चरों के वास्तविक उदाहरण देखेंगे, और मात्रात्मक और गुणात्मक डेटा अनुसंधान में उनकी प्रासंगिकता को समझेंगे।
परिभाषाओं में उतरने से पहले, यह समझना ज़रूरी है कि यह विषय क्यों महत्वपूर्ण है। ऐसे दौर में जब व्यवसाय प्रतिदिन खरबों डेटा बिंदुओं को संसाधित करते हैं, हम डेटा को जिस तरह से वर्गीकृत करते हैं, उसका सटीक निर्णय लेने की हमारी क्षमता पर सीधा प्रभाव पड़ता है। यह खंड नाममात्र डेटा और क्रमिक डेटा के बीच मूलभूत अंतरों का परिचय देता है, जो सांख्यिकीय तर्क और डेटा-संचालित अंतर्दृष्टि दोनों के लिए महत्वपूर्ण हैं।
डेटा प्रकारों को समझना
सभी डेटा असंरचित जानकारी के रूप में शुरू होते हैं। एक बार डेटा संग्रह के माध्यम से व्यवस्थित हो जाने पर, यह आधुनिक डेटा विज्ञान का आधार बन जाता है। डेटा कई रूपों में मौजूद होता है - बाइनरी (0 और 1), टेक्स्ट, चित्र या ऑडियो - और इसका विश्लेषण गुणात्मक और मात्रात्मक, दोनों डेटा तकनीकों के माध्यम से किया जा सकता है। डेटा के प्रकार को पहचानने से उपयुक्त मापन पैमाने और लागू करने योग्य सांख्यिकीय विधियों का निर्धारण करने में मदद मिलती है।
बढ़ती संख्या में विश्लेषक इस बात पर ज़ोर दे रहे हैं कि डेटा के प्रकार को जानना उतना ही ज़रूरी है जितना कि स्वयं डेटा। 2025 के PwC सर्वेक्षण के अनुसार, 84% डेटा पेशेवरों ने बताया कि डेटा प्रकारों को गलत लेबल करने से विश्लेषण के परिणाम त्रुटिपूर्ण होते हैं, जिससे उचित डेटा मापन पद्धतियों की आवश्यकता और बढ़ जाती है।
श्रेणीबद्ध और मात्रात्मक डेटा
डेटा सामान्यतः दो प्राथमिक श्रेणियों में आता है: श्रेणीबद्ध और मात्रात्मक।
- श्रेणीबद्ध डेटा (या गुणात्मक डेटा) रंग, लिंग या ब्रांड वरीयता जैसी विशेषताओं का वर्णन करता है। इसमें नाममात्र डेटा और क्रमिक डेटा शामिल हैं।
- मात्रात्मक डेटा (या संख्यात्मक डेटा) में मापन योग्य मान शामिल होते हैं और इसमें अंतराल, अनुपात, असतत और सतत डेटा प्रकार शामिल होते हैं।
नाममात्र, क्रमिक, अंतराल और अनुपात डेटा के बीच अंतर को समझना सही सांख्यिकीय विश्लेषण करने और वैध निष्कर्ष निकालने के लिए महत्वपूर्ण है।
माप के स्तर: नाममात्र, क्रमिक, अंतराल और अनुपात
मनोवैज्ञानिक स्टेनली स्मिथ स्टीवंस ने माप के चार स्तरों को परिभाषित किया है जो आज भी उपयोग में हैं:
- नाममात्र पैमाना (नाममात्र डेटा): क्रम बताए बिना वर्गीकरण करता है। नाममात्र डेटा के उदाहरणों में लिंग, रक्त प्रकार और देश शामिल हैं।
- क्रमिक पैमाना (क्रमिक डेटा): श्रेणियों को सार्थक रूप से क्रमबद्ध करता है, जैसे शिक्षा स्तर या संतुष्टि स्तर, हालांकि रैंकों के बीच अंतराल भिन्न हो सकते हैं।
- अंतराल पैमाना (अंतराल डेटा): समान अंतरालों पर मापे गए संख्यात्मक चरों से संबंधित है, लेकिन वास्तविक शून्य के बिना (उदाहरण के लिए, सेल्सियस में तापमान)।
- अनुपात पैमाना (अनुपात डेटा): इसमें एक वास्तविक शून्य होता है, जो पूर्ण गणितीय संक्रियाओं की अनुमति देता है। उदाहरणों में ऊँचाई, आय और अवधि शामिल हैं।
प्रत्येक मापन पैमाना डेटा को समझने के लिए एक अनूठा दृष्टिकोण प्रदान करता है। नाममात्र और क्रमिक डेटा श्रेणीबद्ध डेटा के अंतर्गत आते हैं, जबकि अंतराल और अनुपात डेटा मात्रात्मक डेटा के अंतर्गत आते हैं।
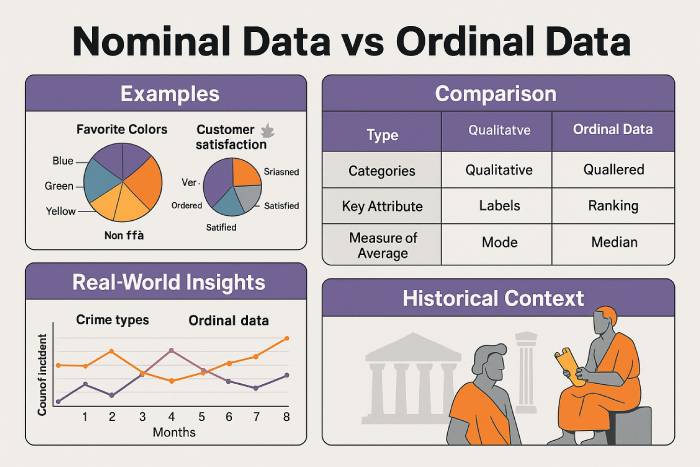
नाममात्र डेटा की व्याख्या
नाममात्र डेटा एक प्रकार का गुणात्मक डेटा है जिसका उपयोग बिना किसी क्रम या रैंकिंग के जानकारी को वर्गीकृत करने के लिए किया जाता है। यह नाममात्र स्तर विपणन, अनुसंधान और स्वास्थ्य सेवा में आम है।
नाममात्र डेटा के उदाहरण:
- लिंग (पुरुष, महिला, अन्य)
- रक्त प्रकार (A, B, AB, O)
- आँखों का रंग (नीला, भूरा, हरा)
- ग्राहक वर्ग (नए, लौटने वाले, प्रीमियम)
डेटा विश्लेषण में, नाममात्र चरों की जाँच बहुलक और आवृत्ति गणनाओं का उपयोग करके की जाती है। बार चार्ट और पाई चार्ट इस श्रेणीबद्ध डेटा को प्रभावी ढंग से प्रस्तुत करते हैं, जिससे अनुपात और प्रवृत्तियों को स्पष्ट करने में मदद मिलती है।
क्रमिक डेटा और उसका महत्व
क्रमिक आँकड़े क्रमबद्ध श्रेणियों को दर्शाते हैं—जैसे संतुष्टि रेटिंग या प्रदर्शन रैंक—जहाँ मानों के बीच की दूरी समान नहीं होती। इस क्रमिक पैमाने का उपयोग अक्सर सर्वेक्षण जैसी डेटा संग्रह तकनीकों में किया जाता है।
क्रमिक डेटा के उदाहरण:
- शिक्षा स्तर (हाई स्कूल, स्नातक, परास्नातक, डॉक्टरेट)
- संतुष्टि स्तर (बहुत असंतुष्ट → बहुत संतुष्ट)
- आर्थिक वर्ग (निम्न → मध्यम → उच्च)
डेटा विश्लेषण में, क्रमिक डेटा मध्यिकाओं, प्रतिशतकों और गैर-पैरामीट्रिक परीक्षणों के उपयोग का समर्थन करता है। क्रमबद्ध बार चार्ट और बिंदु आरेख जैसे विज़ुअलाइज़ेशन स्पष्ट रूप से क्रमबद्ध संबंधों को प्रदर्शित करते हैं। नाममात्र और क्रमिक डेटा के बीच मुख्य अंतर क्रम में है - क्रमिक डेटा में क्रम होता है, नाममात्र डेटा में नहीं।
अंतराल और अनुपात डेटा: मात्रात्मक विश्लेषण
अंतराल और अनुपात डेटा सबसे सटीक मात्रात्मक डेटा प्रकार हैं।
- अंतराल डेटा समान माप अंतराल के साथ एक अंतराल पैमाने का उपयोग करता है लेकिन कोई पूर्ण शून्य नहीं होता है (उदाहरण के लिए, आईक्यू, तापमान)।
- अनुपात डेटा एक अनुपात पैमाने पर काम करता है, जहाँ शून्य का अर्थ है किसी चर का पूर्ण अभाव। उदाहरणों में आय, वज़न या दूरी शामिल हैं।
दोनों डेटा प्रकार उन्नत सांख्यिकीय विश्लेषण जैसे माध्य, विचरण और सहसंबंध की अनुमति देते हैं - जो वर्णनात्मक सांख्यिकी और पूर्वानुमानात्मक मॉडलिंग में आवश्यक है।
असतत बनाम सतत डेटा
मात्रात्मक डेटा भी असतत और सतत डेटा में विभाजित होता है:
- असतत डेटा में गणनीय मान शामिल होते हैं, जैसे ग्राहकों या कारों की संख्या।
- सतत डेटा में एक सीमा के भीतर मापनीय मान शामिल होते हैं, जैसे ऊंचाई या समय।
असतत बनाम क्रमिक डेटा तथा असतत बनाम सतत डेटा के अंतर को पहचानने से डेटा विश्लेषण की सटीकता में सुधार होता है और यह सुनिश्चित होता है कि सही विज़ुअलाइज़ेशन विधियों का उपयोग किया जाए।
डेटा प्रकारों और स्तरों को समझना क्यों महत्वपूर्ण है
नाममात्र, क्रमिक, अंतराल और अनुपात डेटा की उचित पहचान सांख्यिकीय विश्लेषणों की विश्वसनीयता को सीधे प्रभावित करती है। क्रमिक डेटा को केवल संख्यात्मक या नाममात्र के रूप में मानने से गलत जानकारी मिल सकती है। जैसा कि कैलिफ़ोर्निया विश्वविद्यालय की डॉ. लिसा गुयेन कहती हैं, "डेटा प्रकार की गलत व्याख्या मशीन लर्निंग मॉडल में पूर्वाग्रह के मूक कारणों में से एक है।"
2025 के डेलॉइट अध्ययन में पाया गया कि डेटा विज्ञान पहलों में निवेश करने वाली 71% कंपनियों ने डेटा वर्गीकरण और मापन पैमाने की साक्षरता में कर्मचारियों को प्रशिक्षित करने के बाद, अपने निवेश पर औसत दर्जे का सुधार दर्ज किया। यह डेटा संग्रह, वर्गीकरण और व्याख्या में कुशल विश्लेषकों की बढ़ती माँग को दर्शाता है।
विशेषज्ञ राय और 2025 के दृष्टिकोण
आईडीसी (2025) के अनुसार, वैश्विक डेटा उत्पादन 181 ज़ेटाबाइट्स को पार कर गया, जो 2024 से 23% की वृद्धि है। एमआईटी की डॉ मारिया चेन कहती हैं, "नाममात्र डेटा और क्रमिक डेटा के बीच बारीकियों को पहचानना अकादमिक क्षेत्र से परे है - यह लागू विश्लेषण का आधार है।"
यूरोपियन इंस्टीट्यूट ऑफ डेटा साइंस के डॉ. राफेल टोरेस कहते हैं, "भविष्य हाइब्रिड डेटा मॉडलिंग में निहित है - जिसमें बेहतर व्यवहार संबंधी अंतर्दृष्टि के लिए गुणात्मक और मात्रात्मक डेटा को संयोजित किया जाएगा।"
स्टेटिस्टा (2025) की एक रिपोर्ट से पता चला है कि 78% संगठन डेटा-आधारित निर्णय लेने की प्रक्रिया का उपयोग करते हैं, फिर भी लगभग आधे को गलत वर्गीकरण की समस्याओं का सामना करना पड़ता है। यह दर्शाता है कि आधुनिक विश्लेषकों के लिए नाममात्र बनाम क्रमिक डेटा, अंतराल और अनुपात डेटा, और असतत बनाम सतत डेटा जैसे अंतरों में महारत हासिल करना क्यों महत्वपूर्ण है।
दृश्य तालिकाएँ और वास्तविक दुनिया के केस अध्ययन
| डेटा प्रकार | पैमाना | मापन गुण | उदाहरण | में प्रयुक्त |
|---|---|---|---|---|
| नाममात्र डेटा | नाममात्र पैमाना | श्रेणीबद्ध (कोई क्रम नहीं) | लिंग, आँखों का रंग | बाजार विभाजन, सर्वेक्षण |
| क्रमिक डेटा | क्रमसूचक पैमाना | रैंक की गई श्रेणियाँ | शिक्षा स्तर, संतुष्टि | ग्राहक अनुभव, प्रदर्शन समीक्षा |
| अंतराल डेटा | अंतराल पैमाना | समान अंतराल, कोई वास्तविक शून्य नहीं | तापमान (°C), IQ | मनोविज्ञान, जलवायु अध्ययन |
| अनुपात डेटा | अनुपात पैमाना | समान अंतराल, सत्य शून्य | ऊंचाई, वजन, आय | वित्त, इंजीनियरिंग, स्वास्थ्य सेवा |
वास्तविक दुनिया विश्लेषण मामला:
2025 में, एक वैश्विक खुदरा श्रृंखला ने ग्राहक संतुष्टि सर्वेक्षणों के क्रमिक आंकड़ों का उपयोग करके चर्न दरों का अनुमान लगाया। संतुष्टि स्तरों ("बहुत असंतुष्ट" से "बहुत संतुष्ट" तक) का विश्लेषण करके, कंपनी ने जोखिम वाले ग्राहक समूहों की पहचान की और पूर्वानुमानित विश्लेषण मॉडलों का उपयोग करके चर्न दरों में 12% की कमी की।
स्वास्थ्य सेवा क्षेत्र का एक और मामला अनुपात संबंधी आंकड़ों से जुड़ा था। अस्पतालों ने मरीज़ों के ठीक होने में लगने वाले समय पर नज़र रखी और स्टाफ़िंग के स्तर को बेहतर बनाने के लिए वर्णनात्मक आँकड़ों का इस्तेमाल किया, जिससे प्रतीक्षा समय में 18% की कमी आई।
ऐतिहासिक संदर्भ
डेटा वर्गीकरण की अवधारणा 20वीं सदी के मध्य की है, जब मनोवैज्ञानिक स्टेनली स्मिथ स्टीवंस ने 1946 में माप के चार स्तरों की शुरुआत की थी। 2025 में, उनका ढांचा डेटा विज्ञान और सांख्यिकीय विश्लेषण में आधारभूत बना हुआ है, जो आधुनिक मशीन लर्निंग और एआई-संचालित निर्णय प्रणालियों का आधार बना रहा है।
आधुनिक विशेषज्ञ इस बात पर ज़ोर देते हैं कि नाममात्र, क्रमिक, अंतराल और अनुपात डेटा की ऐतिहासिक जड़ें उभरती हुई तकनीकों को सूचित करती रहती हैं। चूँकि एआई प्रणालियाँ डेटा लेबलिंग और वर्गीकरण पर अधिक निर्भर करती हैं, माप पैमानों की सटीक समझ नैतिक और सटीक मॉडल प्रशिक्षण सुनिश्चित करती है।
अंतिम विचार
डेटा विज्ञान के उदय ने डेटा को सही ढंग से वर्गीकृत और व्याख्या करने की क्षमता को पहले से कहीं अधिक मूल्यवान बना दिया है। नाममात्र और क्रमिक डेटा, साथ ही अंतराल और अनुपात पैमानों को समझना, सटीक डेटा विश्लेषण और विश्वसनीय सांख्यिकीय अंतर्दृष्टि का आधार है।
अपने विश्लेषणात्मक कौशल को निखारने के लिए, नई डेटा संग्रह तकनीकों का अन्वेषण करें, कठोर डेटा मापन सिद्धांतों को लागू करें, और गुणात्मक और मात्रात्मक चरों के बीच अंतर करने की अपनी क्षमता को निरंतर निखारें। विश्लेषण का भविष्य उन पेशेवरों पर निर्भर करता है जो जटिल सांख्यिकीय डेटा को सार्थक, क्रियाशील अंतर्दृष्टि में बदल सकते हैं।

